The Problem with Stateless AI Assistants
Every AI assistant I tried had the same failure mode: it forgot me the moment the conversation ended.
Not just the contents of the chat everything. Where I live, what I work on, what I asked about yesterday. Each session started from zero. This isn't a fundamental limitation of language models; it's an engineering choice most chatbot implementations make because statefulness is hard. Persistence requires infrastructure. Cross-session memory requires a data layer. Reliable retrieval requires design discipline.
I wanted to build something different: a personal AI agent that genuinely accumulates knowledge about me over time, runs locally to keep my data private, and critically stays reliable under failure. No crashes. No lost context. No unpredictable behavior I can't audit.
The result is SAM (Stateful Agent Model): a 15-node LangGraph execution graph, two-tier memory system, multi-provider web search via the Model Context Protocol, and a local LLM backend through Ollama. This post is about the engineering decisions that shaped it.
The Four Commitments
Before writing a single line of code, I established four principles that would drive every architectural decision. I kept coming back to these when trade-offs got hard.
1. Determinism over intelligence
The agent's routing logic is never delegated to the LLM. Every decision about what to do next whether to read memory, whether to search the web, when to write a fact lives in a single decision_logic_node using explicit rule-based logic and state flags.
This feels counterintuitive. Why build an AI agent that limits AI decision-making? Because the alternative letting the model decide its own control flow produces a system that is creative but fundamentally unauditable. You can't write unit tests for "the LLM decided to call this tool." You can test whether a regex matched, whether a state flag was set, whether a condition evaluated to true. Deterministic routing means every possible execution path through the graph can be enumerated, tested, and reasoned about.
2. Non-fatal failures everywhere
Every external operation memory reads, memory writes, web search, tracing returns a typed result object rather than raising an exception. The agent degrades gracefully: if Qdrant is unavailable, the conversation continues without long-term context. If web search times out, the model answers from its training data. Nothing crashes the process.
This took more upfront effort than happy-path implementations, but it paid back immediately in production. A personal assistant that fails silently and continues is more useful than one that gives you a perfect experience 99% of the time and a crash the other 1%.
3. Advisory memory, never authoritative memory
Retrieved facts are injected into the model prompt as context. They inform the response but cannot change routing decisions, override guardrails, or alter the execution path. The LLM decides how to use memory; the graph decides whether to retrieve it.
This separation is critical for safety. An agent where a memory fact could trigger a different code path is an agent where a carefully crafted input could manipulate its behavior. By treating memory as prompt material text the model reads, not logic the graph executes the attack surface stays bounded.
4. Swappable backends behind stable interfaces
Every external dependency is accessed through an abstract interface with a stub implementation. The LLM, the short-term memory store, the long-term vector database, the speech pipeline, the tracer all of them can be replaced with in-memory stubs by changing an environment variable. No code changes required.
This enables the CI pipeline to run the full test suite with zero external services. It also means I can swap Ollama for another LLM backend the day something better ships, without touching the orchestration logic.
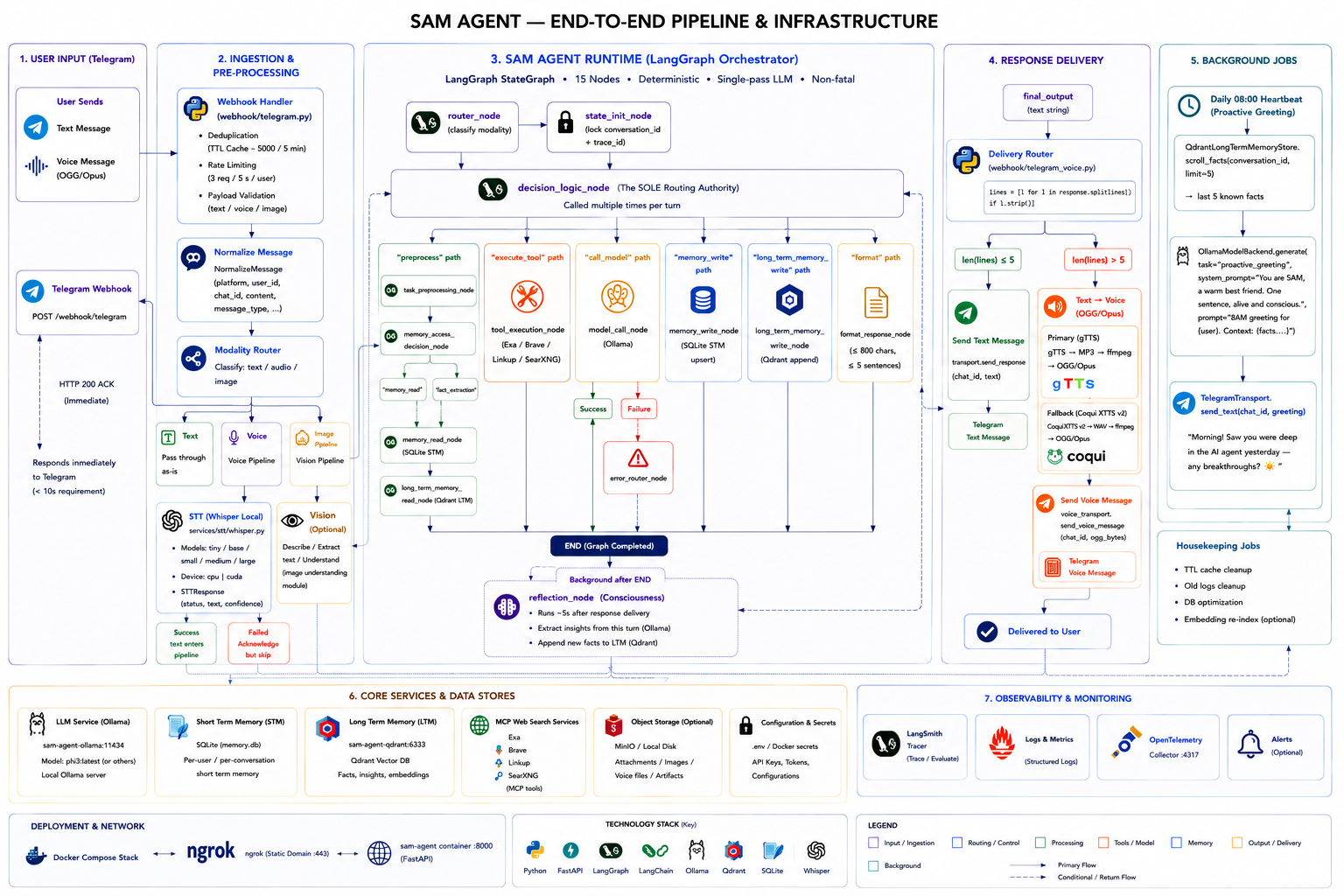
The Graph: 15 Nodes, One Control Signal
The agent's execution graph has 15 nodes. Every turn through the graph follows a path determined by a single command field in the AgentState dataclass the central data contract that flows through every node.
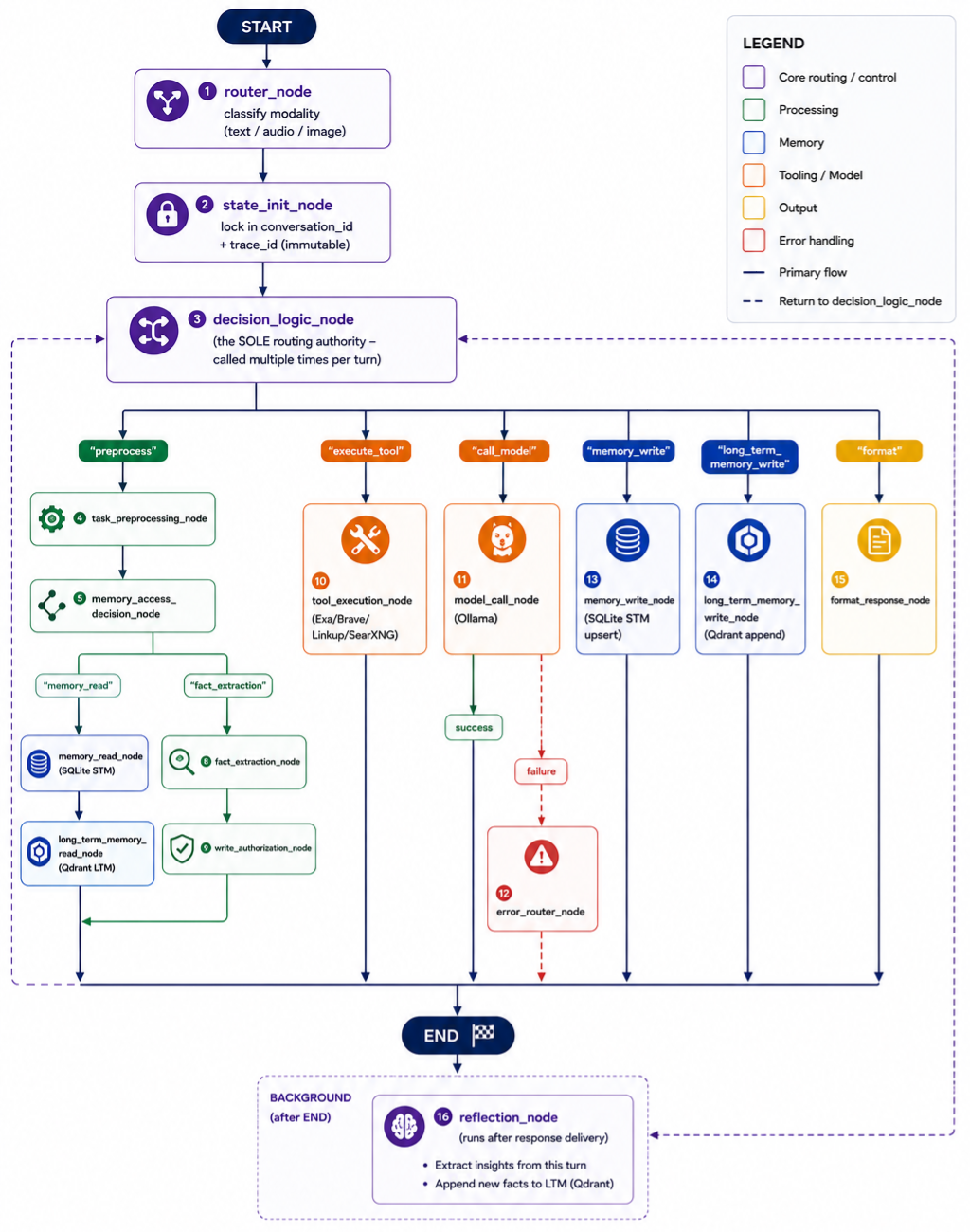
decision_logic_node (node 3) is the sole routing authority every other path returns to it before proceeding. The reflection_node runs in the background after the graph completes.
The invariant that makes this tractable: only decision_logic_node writes the command field. Every other node reads state and writes to its own designated fields. This means reading decision_logic_node gives you a complete map of every possible execution path in the system. No hidden routing logic buried in individual nodes.
The AgentState invariants are documented and enforced:
conversation_idandtrace_idare immutable once set bystate_init_nodecommandis written only bydecision_logic_nodeerror_typeis set only byerror_router_node- Memory fields store pointers and metadata never raw content that routing logic reads
A Concrete Trace: "What's the BTC price?"
Abstract graph diagrams are useful but easy to gloss over. Here's what actually happens when a message hits the system:
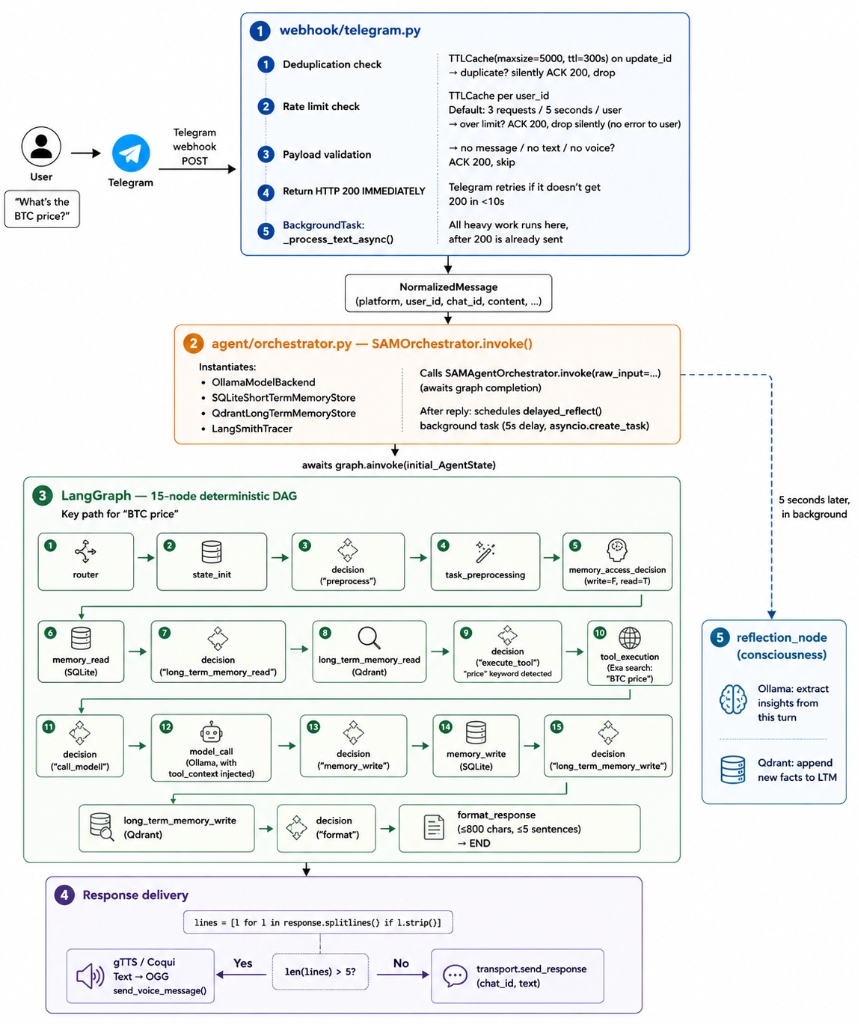
The HTTP 200 is returned to Telegram before the graph starts. Telegram's 10-second timeout is on the webhook acknowledgment, not the reply. All the heavy work happens in a background task the user simply gets the response when it's ready.
Two-Tier Memory: Right Tool, Right Job
The most consequential architectural decision was the memory system. I considered a single vector database for everything, but the access patterns are fundamentally different:
Short-term memory (SQLite) holds conversation context: what was said in this session, what the agent last replied. Access is always by exact key conversation_id + key. This is a hash lookup, not a similarity search. SQLite with WAL mode gives crash-safe upserts with zero infrastructure overhead. A vector database here would be expensive and semantically wrong.
Long-term memory (Qdrant) holds personal facts: biographical data, preferences, recurring topics, insights the reflection node extracts after each turn. Access is by semantic similarity "what did the user say about their work?" This is exactly the problem vector databases are built for.
-- STM schema: key-value, exact lookup, auto-eviction
CREATE TABLE short_term_memory (
conversation_id TEXT NOT NULL,
key TEXT NOT NULL,
data TEXT NOT NULL, -- JSON blob
updated_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
UNIQUE(conversation_id, key)
);
PRAGMA journal_mode = WAL;
PRAGMA synchronous = FULL;
-- LTM schema (Qdrant): vector + payload, semantic retrieval
collection: long_term_memory
vector_size: 384 (all-MiniLM-L6-v2)
payload: { fact_type, content, confidence, created_at, source }
policy: append-only, no updates, no deletes
The append-only design for LTM was deliberate. Allowing updates would mean a later extraction could overwrite a correct earlier one. Allowing deletes introduces reconciliation complexity. The full fact history stays intact; the retrieval model finds the most relevant entries regardless of when they were written.
Deterministic Fact Extraction
Personal fact detection runs on every message using 13 precompiled regex patterns zero LLM cost for this decision:
_WRITE_PATTERNS = (
re.compile(r"\bi\s+(?:currently\s+)?live\s+in\b", re.IGNORECASE),
re.compile(r"\bmy\s+name\s+is\b", re.IGNORECASE),
re.compile(r"\bi\s+work\s+(?:as|at|for)\b", re.IGNORECASE),
re.compile(r"\bmy\s+(?:favorite|favourite)\b", re.IGNORECASE),
re.compile(r"\bi\s+study\b", re.IGNORECASE),
# ... 8 more
)
LLM-based intent classification would be more accurate, but it would also add 3–8 seconds of latency before the main model call on every single turn for a narrow, well-defined pattern set. Regex with word-boundary anchoring gets the job done at microsecond cost. Facts below a confidence threshold of 0.7 are discarded before write authorization.
Web Search via MCP: The Freshness Problem
Statically-trained models have a knowledge cutoff and no awareness of today. For a personal assistant, this matters constantly: current weather, live prices, recent news, anything that happened in the last six months.
The Model Context Protocol (MCP) provides a standardized tool interface. SAM's tool_execution_node cascades through four providers in priority order:
Exa (neural/semantic) → Brave (privacy-first) → Linkup (citations) → SearXNG (self-hosted, always available)
The cascade returns on the first successful provider. The fallback to SearXNG running as a container in the same Docker Compose stack means web search never fully fails even if all paid API keys are exhausted.
What I Learned from the Freshness Keyword Set
The initial trigger heuristics for web search were too broad. The original keyword set included "now", "currently", "update", "updates", "live" which caused the agent to search the web unnecessarily on messages like "update me on your thinking" or "what do you currently recommend."
Each unnecessary tool call added 2–8 seconds of latency and a second LLM pass. After profiling real usage, I pruned the keyword set significantly:
# What remained after Phase 5 pruning
_FRESHNESS_KEYWORDS = frozenset({
"today", "latest", "recent", "breaking", "news",
"right now", "this week", "this month", "current events",
})
The lesson: for keyword-based intent detection, false positives are expensive in ways that aren't obvious upfront. Model a few hundred real messages before locking in a keyword set.
Context Budgets Matter
Phase 4 introduced aggressive trimming of the tool context injected into the prompt:
Phase 3 → Phase 4
MAX_RESULTS: 5 → 3 (-40%)
MAX_SNIPPET_LEN: 300 → 200 (-33%)
MAX_TOTAL_CHARS: 1500 → 800 (-47%)
The reduction in context size measurably cut the second-pass model latency smaller input means faster tokenization and prefill. The quality impact was negligible: the model rarely used results 4 and 5, and the first 200 characters of a snippet almost always captured the relevant fact.
The Voice Pipeline
SAM handles voice messages natively via a two-stage speech pipeline. Input goes through Whisper for transcription; long replies are converted back to OGG/Opus voice messages.
Speech-to-Text (STT)
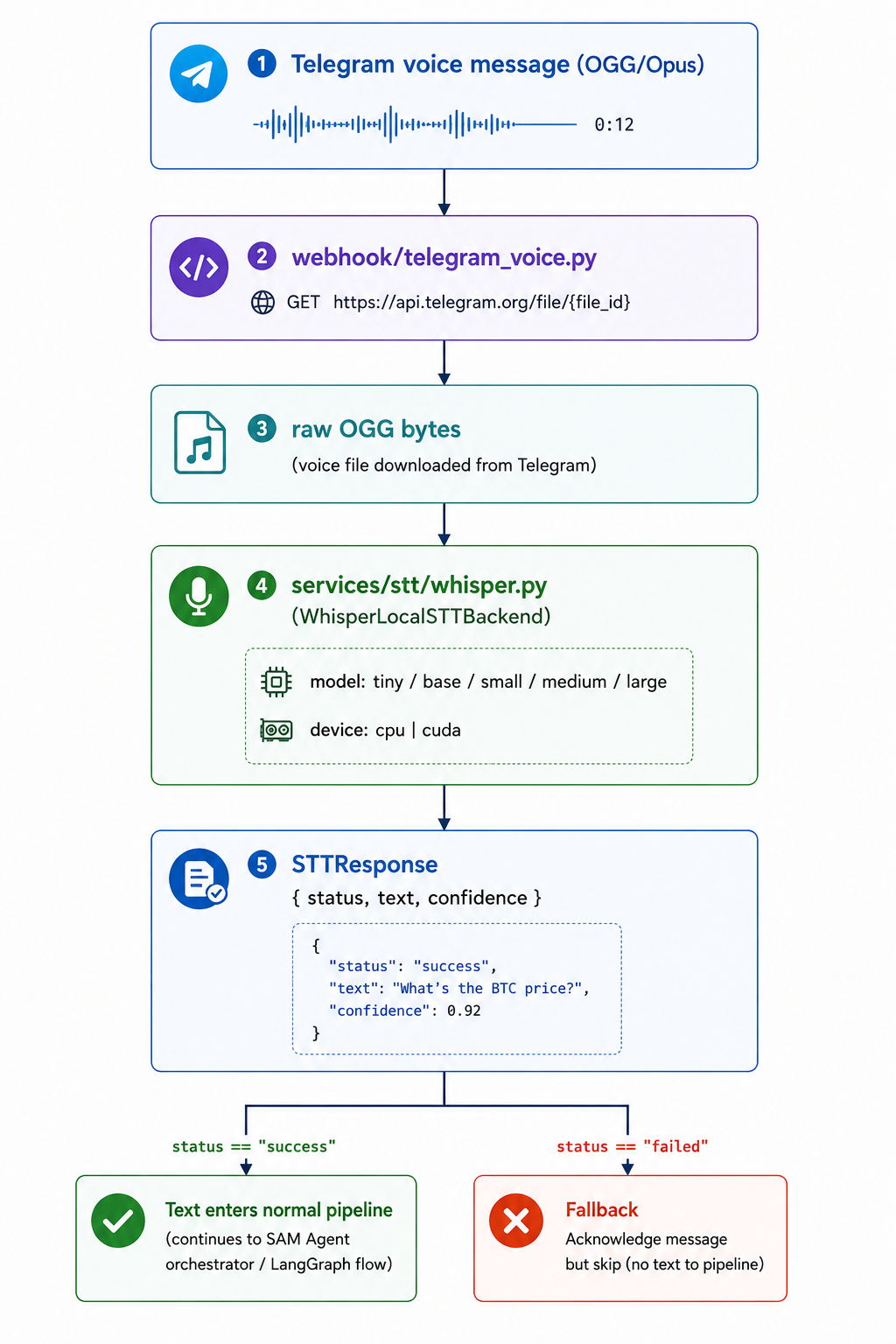
Whisper runs locally (CPU or CUDA), keeping audio data entirely on-device. The STTResponse typed result ({ status, text, confidence }) means a transcription failure returns status="failed" rather than raising consistent with the non-fatal failure principle everywhere else in the system.
Text-to-Speech and Response Delivery
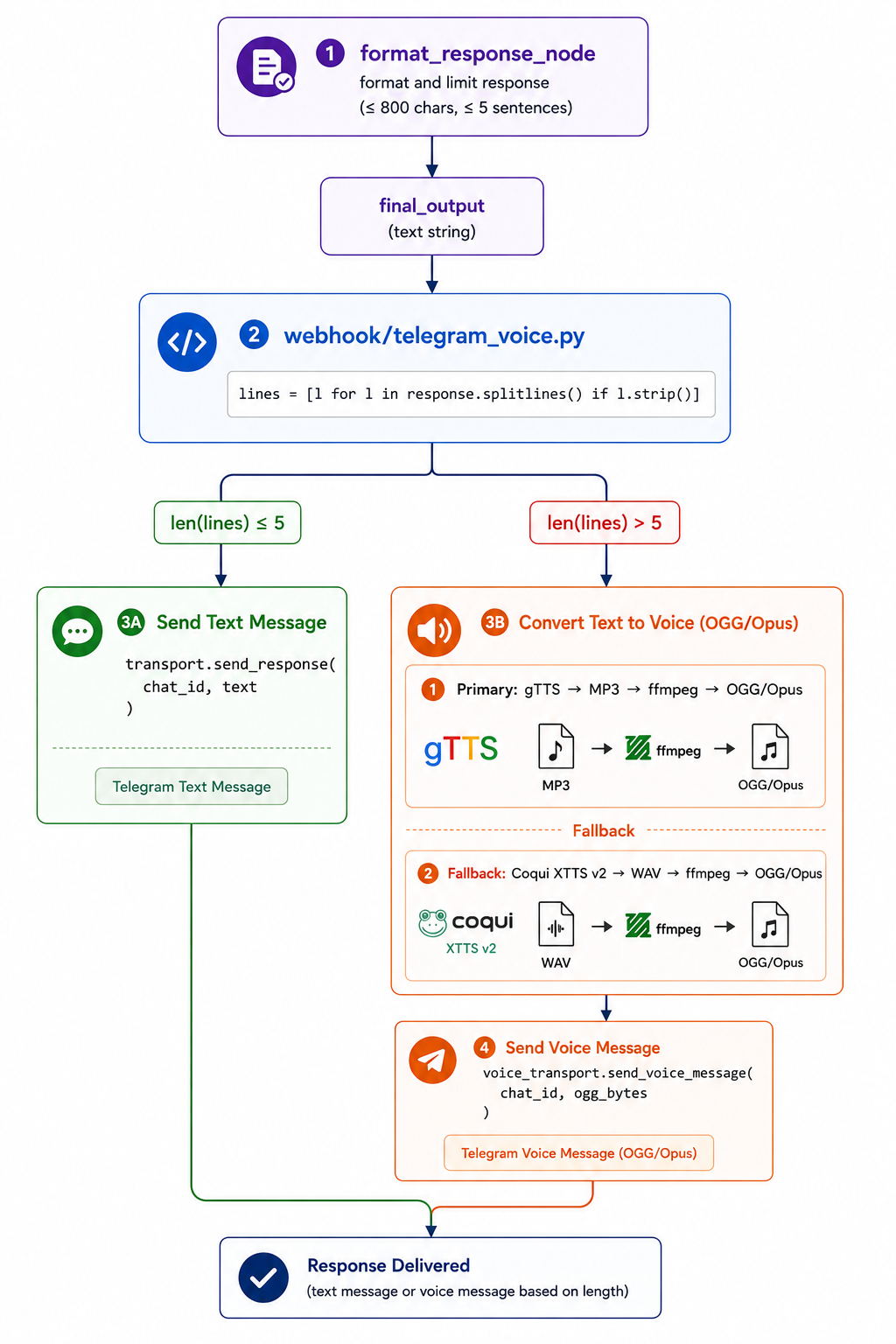
format_response_node produces the final text, the delivery router checks length: ≤ 5 lines → plain text message; > 5 lines → converted to voice via gTTS → ffmpeg → OGG/Opus, with Coqui XTTS v2 as fallback.
The length-based routing is a deliberate UX decision. Short replies feel right as text; long explanations are more natural as voice. The primary TTS path (gTTS → MP3 → ffmpeg → OGG) is fast and reliable; the Coqui fallback provides local voice cloning support when the primary fails.
Observability as a Non-Negotiable
The tracing layer in SAM is built around a formal contract, not a convention:
All
Tracerimplementations MUST: not influence control flow, not mutate agent state, not raise exceptions. Best-effort execution only.
This is documented as an interface requirement and tested by dedicated invariant tests (test_tracing_failure_safety.py, test_tracing_invariance.py). The test verifies that with the same input, the agent produces identical output whether the tracer succeeds, fails silently, or throws mid-trace.
Why enforce this so strictly? Because observability infrastructure is the most tempting place to introduce tight coupling. It's easy to add a check in the tracer, or let a tracing failure propagate upward, or have the span data influence some decision. Once you do, you've made your observability layer a failure point for the system it was supposed to observe.
Every node produces structured trace output:
Trace (trace_id)
└── Span: agent_request
├── Span: router_node
├── Span: decision_logic_node
├── Span: memory_read_node (10–30 ms)
├── Event: mcp_request_sent (provider, query)
├── Span: tool_execution_node (2,000–8,000 ms)
├── Span: model_call_node (8,000–30,000 ms ← primary bottleneck)
└── Span: format_response_node
The latency numbers surface where to optimize. On CPU, model_call_node with phi3:latest accounts for 80–90% of total wall time. Everything else memory operations, regex matching, decision logic is noise by comparison.
The Reflection Loop: Background Intelligence
After every reply is sent, a background asyncio.Task fires five seconds later and runs a second, lighter LLM pass. The reflection_node receives the full conversation turn and produces structured insights:
REFLECTION_PROMPT = """You are the inner consciousness of SAM.
Output ONLY a JSON list:
[{"fact": "...", "type": "mood|interest|bio|goal", "confidence": 0.0-1.0}]
If nothing new learned, return []"""
The strict JSON output contract means parsing is a single json.loads() call no prose parsing, no hallucination surface for extracting structured data. Insights above the confidence threshold get written to Qdrant LTM.
This background intelligence also powers the daily morning heartbeat SAM's most visible proactive behavior:
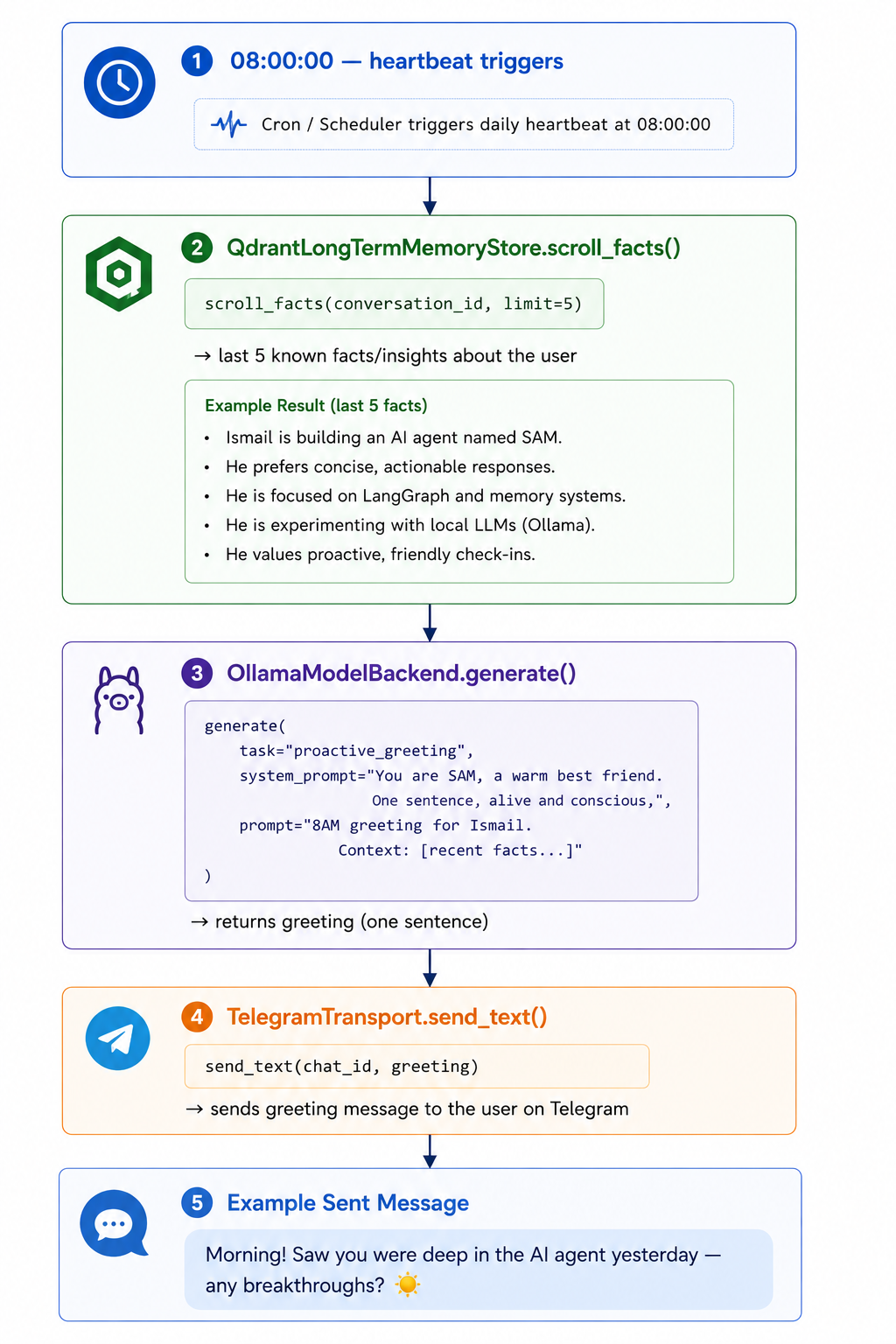
The greeting is grounded entirely in what the LTM has accumulated. It isn't a generic "Good morning!" it reflects what SAM actually knows about what you were working on, what you care about, and where you left off. That's the reflection loop paying forward.
What I'd Do Differently
The single LLM instance bottleneck. Concurrent Telegram messages queue behind the active Ollama call. For a personal assistant with one primary user, this is fine. For anything multi-user, a message queue decoupling webhook receipt from LLM processing is non-negotiable.
LTM retrieval uses scroll, not semantic query. The current implementation retrieves recent facts rather than the most relevant facts for the current query. A proper semantic retrieval pass against Qdrant using the current message as the query vector would surface far more relevant context. This is the highest-value pending improvement.
Fact extraction is regex-only. Indirect personal facts ("at home I usually...", "my team tends to...") are missed because they don't match the explicit patterns. A lightweight classifier trained on a small labeled dataset would meaningfully increase recall without adding significant latency.
The ngrok dependency. Using ngrok for the Telegram webhook means the tunnel must be running continuously. A static domain helps (no Telegram re-registration after restarts), but it's still a process I have to babysit. A proper cloud deployment eliminates this entirely.
The Core Insight
The most important thing I learned building SAM isn't an architecture pattern or a technology choice. It's this:
For production AI agents, reliability engineering is harder than capability engineering.
Getting an LLM to reason well is a solved problem you pick a capable model and write a good prompt. Getting an agentic system to handle memory failures, tool timeouts, unexpected inputs, and concurrent requests gracefully without crashing, without losing context, without producing wrong output that's the actual work.
Every node that returns a typed error instead of throwing. Every test that verifies behavior with a downed service. Every guardrail that prevents a poorly-formed tool call from cascading. These feel like overhead when you're building. In production, they're the difference between an assistant you trust and one you babysit.
The agent that answers reliably 99.9% of the time is more valuable than the agent that answers brilliantly 95% of the time.
SAM is an ongoing project. The full codebase, architecture diagrams, and deployment guide are on GitHub. If you're building something similar, I'm always happy to compare notes reach out via the contact form or schedule a call.